Table of Contents
- Installation
- Minimal example
- Chapter breaks
- Changing settings via -V option
- Syntax highlighting
- Bullet styling
- PDF properties
- Adding table of contents
- Resource links
Either you’ve already heard of pandoc or if you have searched online for markdown to pdf or similar, you are sure to come across pandoc. This tutorial will give you a basic idea of using pandoc to generate pdf from GitHub style markdown file. The main purpose is to highlight what customizations I did to generate pdf for self-publishing my ebooks. It wasn’t easy to arrive at the set-up I ended up with, so I hope this will be useful for those looking to use pandoc to generate pdf. Specifically aimed at technical books that has code snippets.
Installation
I use Ubuntu, as far as I remember, the below steps are enough to work for the demos in this tutorial. If you get an error or warning, search that issue online and you’ll likely find what else has to be installed.
I first downloaded deb file from pandoc: releases and installed it. Followed by packages needed for pdf generation.
$ # current version is 2.7, I had installed last year with 2.3
$ sudo gdebi ~/Downloads/pandoc-2.3-1-amd64.deb
$ # note that download size is 750+ MB
$ sudo apt install texlive-xetex
$ sudo apt install librsvg2-bin
$ sudo apt install texlive-math-extra
For more details and guide for other OS, refer to pandoc: installation
Minimal example
Once pandoc is working on your system, try generating a sample pdf without any customization.
 See learnbyexample.github.io repo for all the input and output files referred in this tutorial
See learnbyexample.github.io repo for all the input and output files referred in this tutorial
$ pandoc sample_1.md -f gfm -o sample_1.pdf
Here sample_1.md is input markdown file and -f is used to specify that the input format is GitHub style markdown. The -o option specifies the output file type based on extension. The default output is probably good enough. But has shortcomings like hyperlinks and inline code are hard to distinguish, chapters are not separated, etc.
pandoc has its own flavor of markdown with many useful extensions, see pandoc: pandocs-markdown for details. GitHub style markdown is recommended if you wish to use the same source (or with minor changes) in multiple places.
It is advised to use markdown headers in order without skipping - for example, H1 for chapter heading and H2 for chapter sub-section, etc is fine. H1 for chapter heading and H3 for sub-section is not. Using the former can give automatic index navigation on pdf readers.
On Evince reader, the index navigation for above sample looks like this:
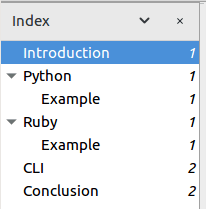
Chapter breaks
As observed from previous demo, by default there are no chapter breaks. Searching for a solution online, I got this piece of tex code:
\usepackage{sectsty}
\sectionfont{\clearpage}
This can be added using -H option. From pandoc manual,
-H FILE, –include-in-header=FILE
Include contents of FILE, verbatim, at the end of the header. This can be used, for example, to include special CSS or JavaScript in HTML documents. This option can be used repeatedly to include multiple files in the header. They will be included in the order specified. Implies –standalone.
The pandoc invocation now looks like:
$ pandoc sample_1.md -f gfm -H chapter_break.tex -o sample_1_chapter_break.pdf
You can add further customization to headings, for example use \sectionfont{\underline\clearpage} to underline chapter names or \sectionfont{\LARGE\clearpage} to allow chapter names to get even bigger. Here’s some more links to play with:
Changing settings via -V option
-V KEY[=VAL], –variable=KEY[:VAL]
Set the template variable KEY to the value VAL when rendering the document in standalone mode. This is generally only useful when the –template option is used to specify a custom template, since pandoc automatically sets the variables used in the default templates. If no VAL is specified, the key will be given the value true.
The -V option allows to change variable values to customize settings like page size, font, link color, etc. As more settings are changed, better to use a simple script to call pandoc instead of typing the whole command on terminal.
#!/bin/bash
pandoc "$1" \
-f gfm \
--include-in-header chapter_break.tex \
-V linkcolor:blue \
-V geometry:a4paper \
-V geometry:margin=2cm \
-V mainfont="DejaVu Serif" \
-V monofont="DejaVu Sans Mono" \
--pdf-engine=xelatex \
-o "$2"
mainfontis for normal textmonofontis for code snippetsgeometryfor page size and marginslinkcolorto set hyperlink color- to increase default font size, use
-V fontsize=12pt- See stackoverflow: change font size if you need even bigger size options
Using xelatex as the pdf-engine allows to use any font installed in the system. One reason I chose DejaVu was because it supported Greek and other Unicode characters that were causing error with other fonts. See tex.stackexchange: Using XeLaTeX instead of pdfLaTeX for some more details.
The pandoc invocation is now through a script:
$ chmod +x md2pdf.sh
$ ./md2pdf.sh sample_1.md sample_1_settings.pdf
Do compare the pdf generated side by side with previous output before proceeding.
 On my system,
On my system, DejaVu Serif did not have italic variation installed, so I had to use sudo apt install ttf-dejavu-extra to get it.
Syntax highlighting
One option to customize syntax highlighting for code snippets is to save one of the pandoc themes and editing it. See stackoverflow: What are the available syntax highlighters? for available themes and more details (as a good practice on stackoverflow, go through all answers and comments - the linked/related sections on sidebar are useful as well).
$ pandoc --print-highlight-style=pygments > pygments.theme
Edit the above file to customize the theme. Use sites like colorhexa to help with color choices, hex values, etc. For this demo, the below settings are changed:
# by default, background is same as normal text
# change it to a shade of gray to easily distinguish code and text
"background-color": "#f8f8f8",
# change italic to false, messes up comments with slashes
# change comment text-color to yet another shade of gray
"Comment": {
"text-color": "#9c9c9c",
"background-color": null,
"bold": false,
"italic": false,
"underline": false
},
Inline code
Similar to changing background color for code snippets, I found a solution online to change background color for inline code snippets.
\usepackage{fancyvrb,newverbs,xcolor}
\definecolor{Light}{HTML}{F4F4F4}
\let\oldtexttt\texttt
\renewcommand{\texttt}[1]{
\colorbox{Light}{\oldtexttt{#1}}
}
Add --highlight-style pygments.theme and --include-in-header inline_code.tex to the script and generate the pdf again.
With pandoc sample_2.md -f gfm -o sample_2.pdf the output would be:

With ./md2pdf_syn.sh sample_2.md sample_2_syn.pdf the output is:

For my Python re(gex)? book, by chance I found that using ruby instead of python for REPL code snippets syntax highlighting was better. Snapshot from ./md2pdf_syn.sh sample_3.md sample_3.pdf result is shown below. For python directive, string output gets treated as a comment and color for boolean values isn’t easy to distinguish from string values. The ruby directive treats string value as expected and boolean values are easier to spot.
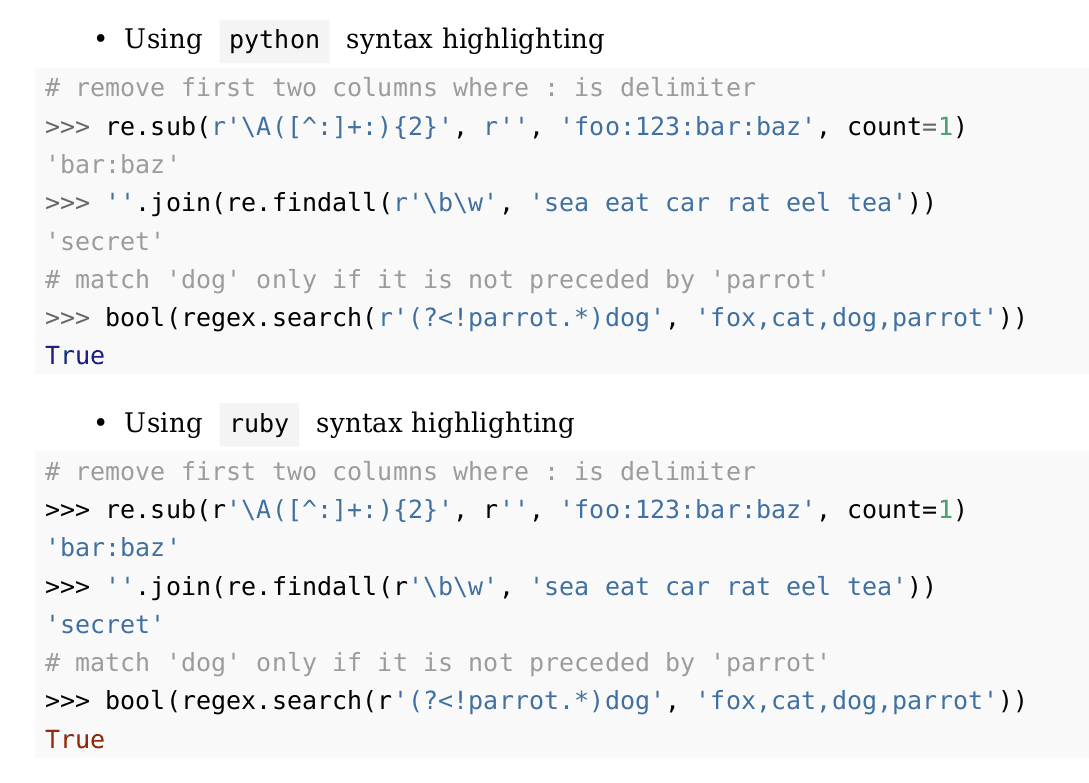
Bullet styling
This stackoverflow Q&A helped for bullet styling.
\usepackage{enumitem}
\usepackage{amsfonts}
% level one
\setlist[itemize,1]{label=$\bullet$}
% level two
\setlist[itemize,2]{label=$\circ$}
% level three
\setlist[itemize,3]{label=$\star$}
Comparing pandoc sample_4.md -f gfm -o sample_4.pdf vs ./md2pdf_syn_bullet.sh sample_4.md sample_4_bullet.pdf gives:

PDF properties
This tex.stackexchange Q&A helped to change metadata. See also pspdfkit: What’s Hiding in Your PDF? and discussion on HN.
\usepackage{hyperref}
\hypersetup{
pdftitle={My awesome book},
pdfauthor={learnbyexample},
pdfsubject={pandoc},
pdfkeywords={pandoc,pdf,xelatex}
}
./md2pdf_syn_bullet_prop.sh sample_4.md sample_4_bullet_prop.pdf gives:
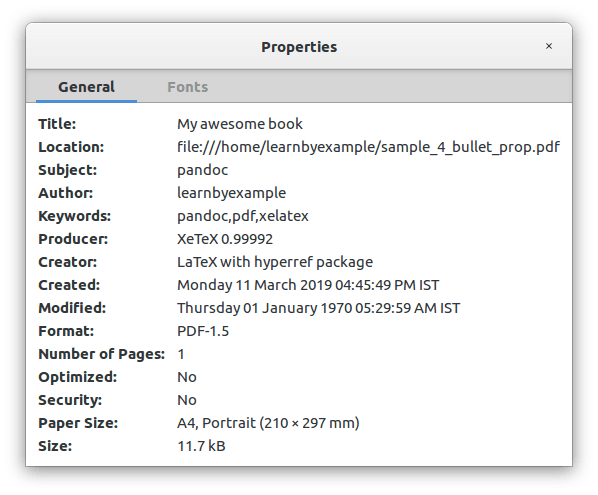
Adding table of contents
There’s a handy option --toc to automatically include table of contents at top of the generated pdf. You can control number of levels using --toc-depth option, the default is 3 levels. You can also change the default string Contents to something else using -V toc-title option.
./md2pdf_syn_bullet_prop_toc.sh sample_1.md sample_1_toc.pdf gives:

However, if you want to add something prior to table of contents (cover image for example), you need to hack stuff. As far as I know, there’s no inbuilt method. The -B option only allows verbatim inclusion, whereas we need markdown here. The only cover image option I see is --epub-cover-image but we need pdf here. I arrived at a workaround after about a day of trying things - the solution looks simple, but I just didn’t know what is possible until I went through multiple options and this one worked.
For this example,  is added to sample_1.md at the top to create input markdown file. The modified script now looks like:
#!/bin/bash
pandoc "$1" \
-f gfm \
--toc \
--include-in-header chapter_break.tex \
--include-in-header inline_code.tex \
--include-in-header bullet_style.tex \
--include-in-header pdf_properties.tex \
--highlight-style pygments.theme \
-V toc-title='Table of contents' \
-V linkcolor:blue \
-V geometry:a4paper \
-V geometry:margin=2cm \
-V mainfont="DejaVu Serif" \
-V monofont="DejaVu Sans Mono" \
--pdf-engine=xelatex \
-o temp.tex
fn="${2%.*}"
perl -0777 -pe \
's/begin\{document\}\n\n\K(.*?^\}$)(.+?)\n/$2\n\\thispagestyle{empty}\n\n$1\n/ms' \
temp.tex > "$fn".tex
xelatex "$fn".tex &> /dev/null
xelatex "$fn".tex &> /dev/null
rm temp.tex "$fn".{tex,toc,aux,log}
The pandoc command is changed to produce tex output instead of pdf. The perl script will switch the positions of cover image and table of contents. Also, \thispagestyle{empty} is added to avoid page number from showing up with cover image, see also tex.stackexchange: clear page. See my tutorial on perl one-liners if you are interested in learning how to write such powerful commands.
After modifying the tex file, xelatex command is directly used to get the pdf output. For some reason, the table of contents goes awry but gives correct output if the command is called twice! The output file is named same as input, but with extension changed from tex to pdf. Finally, the temporary files are removed.
The bash script invocation is now ./md2pdf_syn_bullet_prop_toc_cover.sh sample_5.md sample_5.pdf.
After posting the above solution, I realized that for simple content like cover image, you can use tex file and include it verbatim instead of hacking and calling xelatex twice, etc. For above example, use sample_1.md instead of sample_5.md as input markdown. Create a tex file with content shown below:
\includegraphics{cover.png}
\thispagestyle{empty}
Then, modify the md2pdf_syn_bullet_prop_toc.sh script by adding --include-before-body cover.tex and tada - you get the cover image before table of contents in a much easier way than hacking intermediate tex file.
You’ll need at least one image in input markdown file, otherwise settings won’t apply to the cover image and you may end up with weird output. And be careful to use escapes if the image path can contain tex metacharacters.
Resource links
- pandoc: manual
- pandoc: demos
- pandoc: tips and tricks
- tex.stackexchange: How to change the background color and border of a blockquote?
- tex.stackexchange: Change section fonts
More options for generating ebooks:
- pandoc-latex-template - a clean pandoc LaTeX template to convert your markdown files to PDF or LaTeX
- Asciidoctor
- Sphinx
- Bookdown
- emacs orgmode
- Markdeep
Miscellaneous
- Vim is saving me hours of work when writing books & courses
- Writing a Book with Unix
- askubuntu: How do I install fonts?
- tex.stackexchange: What best combination of fonts for Serif, Sans, and Mono do you recommend?
- LATEX font catalogue
- Tools to support markdown authoring
- picular: search engine for colors
- ebooks.stackexchange